


Hey! I am right now at xAI, pushing its multi-modal frontier.
I was a Research Scientist at Meta FAIR, working on on pre-training and understanding visual representations.
I got my PhD from the Language Technology Institute, Carnegie Mellon University, while working at the Robotics Institute. I graduated with a bachelor's degree in computer science from Zhejiang University, China.
Publications with Extra Materials
For better maintenance and more clear purpose of this page, I am only listing publications with extra materials such as code link below in reverse chronological order.
For a complete, up-to-date list of publications, please check out Google Scholar or arXiv instead.
| Information | Links | |
|---|---|---|
 |
Philippe Hansen-Estruch, David Yan, Ching-Yao Chung, Orr Zohar, Jialiang Wang, Tingbo Hou, Tao Xu, Sriram Vishwanath, Peter Vajda, Xinlei Chen. Learnings from Scaling Visual Tokenizers for Reconstruction and Generation. ICML, 2025. | [Link] |
 |
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun and Zhuang Liu. Transformers without Normalization. arXiv, 2025. | [Link] [Code] |
 |
Alexander C. Li, Yuandong Tian, Beidi Chen, Deepak Pathak, Xinlei Chen. On the Surprising Effectiveness of Attention Transfer for Vision Transformers. NeurIPS, 2024. | [Link] [Code] |
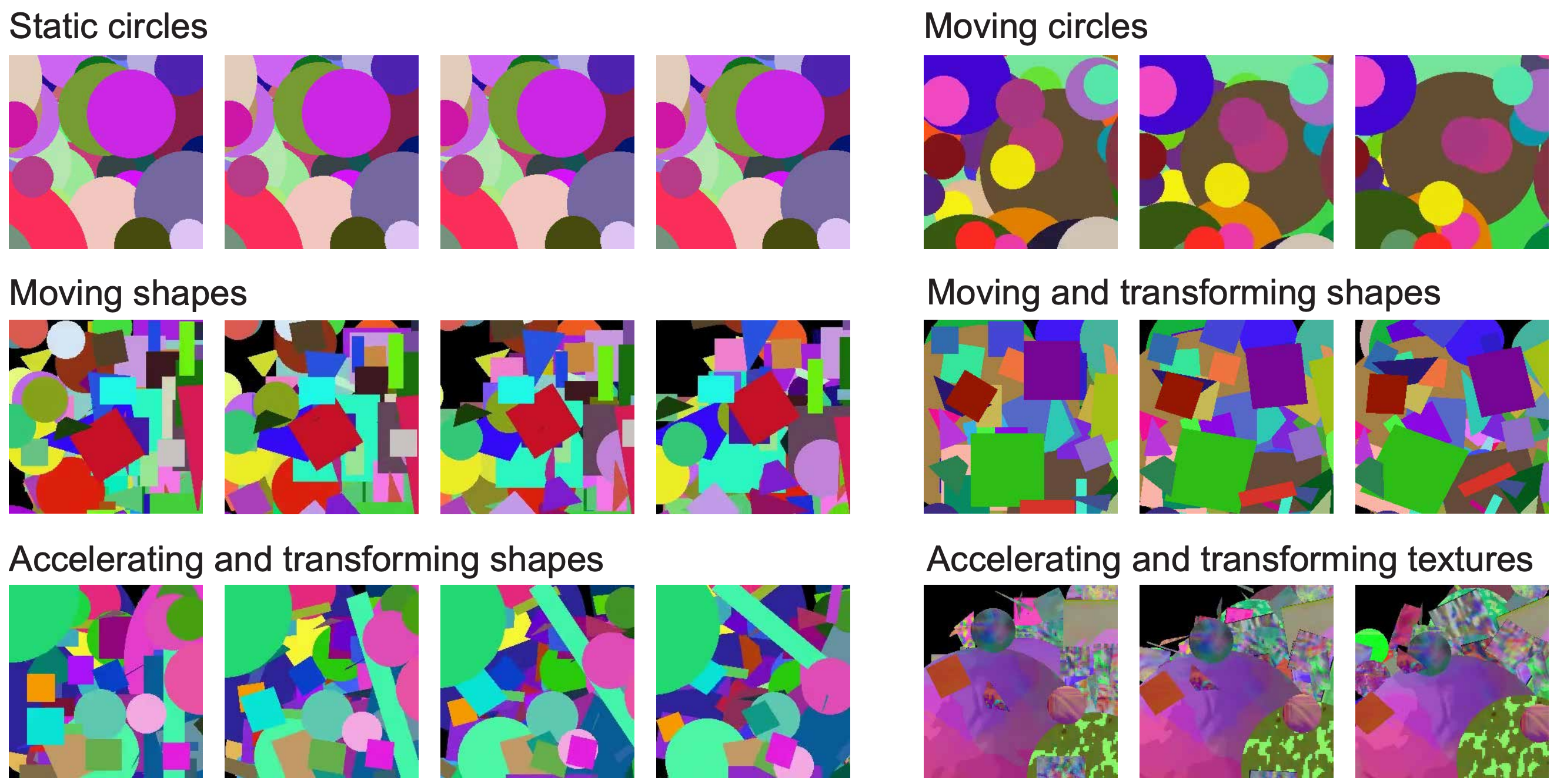 |
Xueyang Yu, Xinlei Chen, Yossi Gandelsman. Learning Video Representations without Natural Videos. ArXiv, 2024. | [Link] [Project] |
 |
Lirui Wang, Xinlei Chen, Jialiang Zhao, Kaiming He. Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformers. NeurIPS, 2024. Spotlight. | [Link] [Project] [Code] |
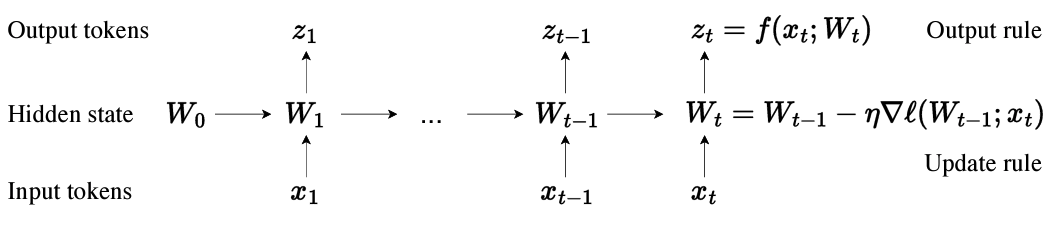 |
Yu Sun*, Xinhao Li*, Karan Dalal*, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen†, Xiaolong Wang†, Sanmi Koyejo†, Tatsunori Hashimoto†, Carlos Guestrin†. Learning to (Learn at Test Time): RNNs with Expressive Hidden States. ArXiv, 2024. | [Link] [Code(PyTorch)] [Code(Jax)] |
 |
Duy-Kien Nguyen, Mahmoud Assran, Unnat Jain, Martin Oswald, Cees Snoek, Xinlei Chen. An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels. ArXiv, 2024. | [Link] |
 |
Mingjie Sun, Xinlei Chen, Zico Kolter, Zhuang Liu. Massive Activations in Large Language Models. CoLM, 2024. | [Link] [Project] [Code] |
 |
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran†, Nicolas Ballas†. Revisiting Feature Prediction for Learning Visual Representations from Video. Meta, 2024. | [Link] [Link] [Code] |
 |
Xinlei Chen, Zhuang Liu, Saining Xie, Kaiming He. Deconstructing Denoising Diffusion Models for Self-Supervised Learning. ArXiv, 2024. | [Link] |
 |
Duy-Kien Nguyen, Vaibhav Aggarwal, Yanghao Li, Martin Oswald, Alexander Kirillov, Cees Snoek, Xinlei Chen. R-MAE: Regions Meet Masked Autoencoders. The 12th International Conference on Learning Representations (ICLR), 2024. | [Link] [Code] |
 |
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. The 36th Conference on Computer Vision and Pattern Recognition (CVPR), 2023. | [Link] [Code] |
 |
Ronghang Hu, Shoubhik Debnath, Saining Xie, Xinlei Chen. Exploring Long-Sequence Masked Autoencoders. ArXiv, 2022. | [Link] [Code] |
 |
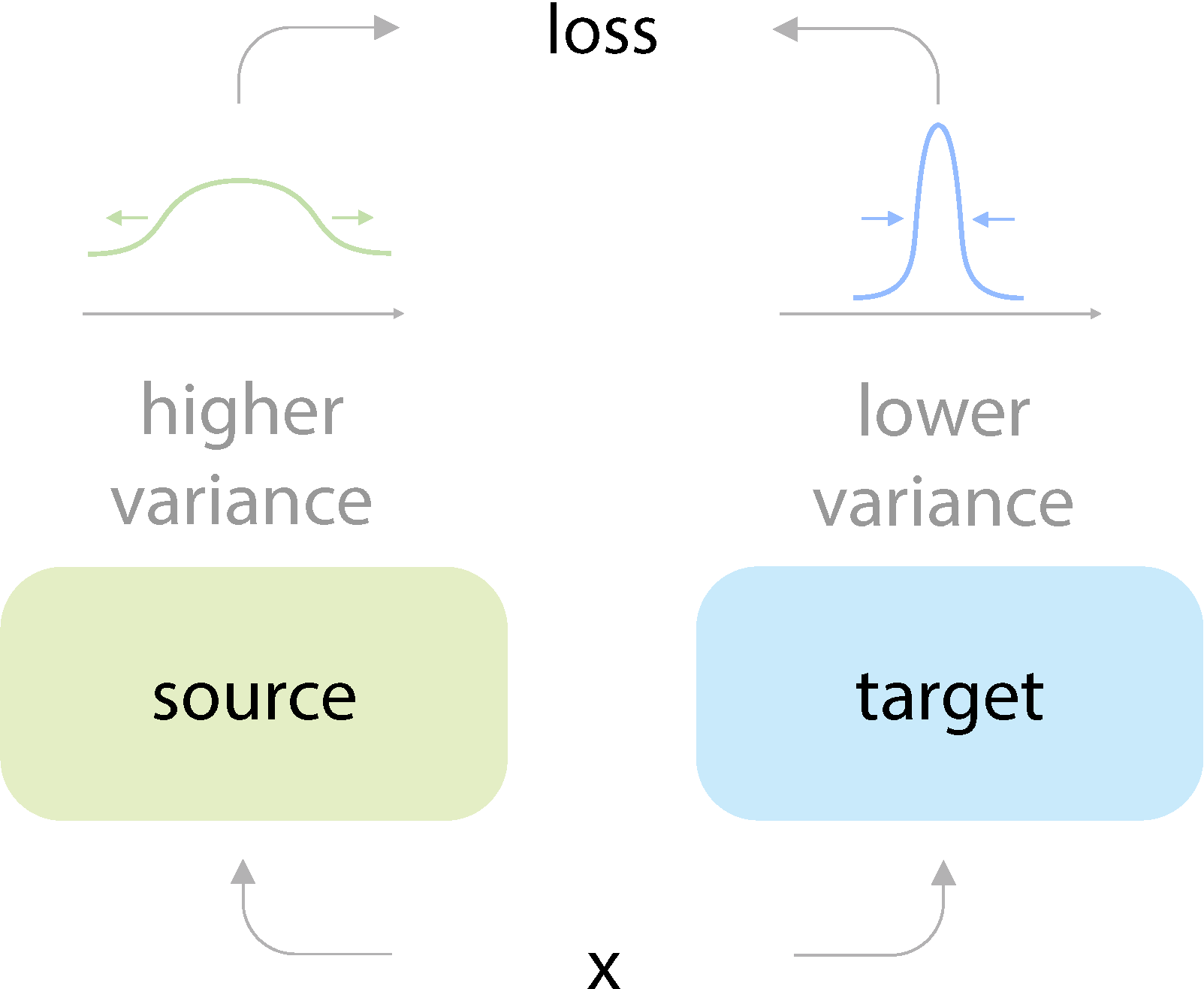
Yossi Gandelsman*, Yu Sun*, Xinlei Chen, Alexei Efros. Test-Time Training with Masked Autoencoders. The 36th Conference on Neural Information Processing Systems (NeurIPS), 2022. | [Link] [Project] [Code] |
 |
Xiao Wang*, Haoqi Fan*, Yuandong Tian, Daisuke Kihara, Xinlei Chen. On the Importance of Asymmetry for Siamese Representation Learning. The 35th Conference on Computer Vision and Pattern Recognition (CVPR), 2022. | [Link] [Code] |
 |
Yutong Bai, Xinlei Chen, Alexander Kirillov, Alan Yuile, Alex Berg. Point-Level Region Contrast for Object Detection Pre-Training. The 35th Conference on Computer Vision and Pattern Recognition (CVPR), 2022. Oral, Best Paper Finalist. | [Link] [Code] |
 |
Kaiming He*†, Xinlei Chen*, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick. Masked Autoencoders Are Scalable Vision Learners. The 35th Conference on Computer Vision and Pattern Recognition (CVPR), 2022. Oral, Best Paper Finalist. | [Link] [Code] |
 |
Yanghao Li, Saining Xie, Xinlei Chen, Piotr Dollár, Kaiming He, Ross Girshick. Benchmarking Detection Transfer Learning with Vision Transformers. ArXiv, 2021 | [Link] [Code] |
 |
Xinlei Chen*, Saining Xie*, Kaiming He. An Empirical Study of Training Self-Supervised Vision Transformers. The 18th International Conference on Computer Vision (ICCV), 2021. Oral. | [Link] [Code] |
 |
Yuandong Tian, Xinlei Chen, Surya Ganguli. Understanding Self-supervised Learning Dynamics without Contrastive Pairs. The 38th International Conference on Machine Learning (ICML), 2021. Long Oral, Outstanding Paper Honorable Mention. | [Link] [Video] [Code] |
 |
Xinlei Chen, Kaiming He. Exploring Simple Siamese Representation Learning. The 34th Conference on Computer Vision and Pattern Recognition (CVPR), 2021. Oral, Best Paper Honorable Mention. | [Link] [Code] |
 |
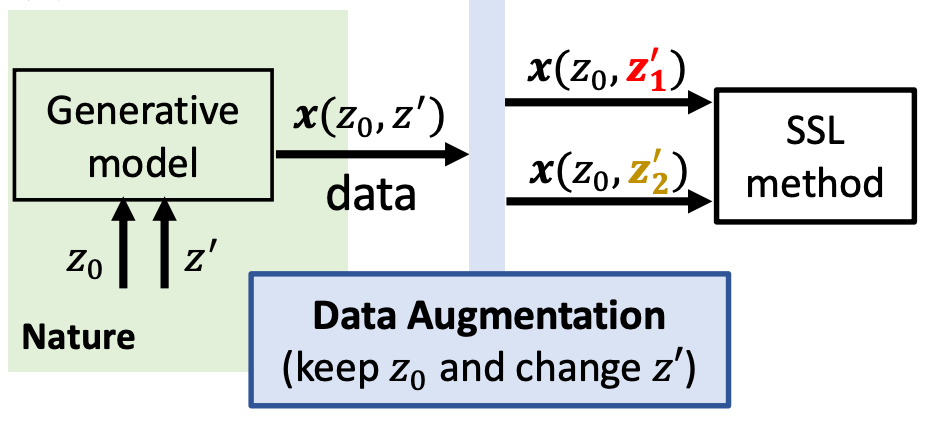
Kenneth Marino, Xinlei Chen, Devi Parikh, Abhinav Gupta, Marcus Rohrbach. KRISP: Integrating Implicit and Symbolic Knowledge for Open-Domain Knowledge-Based VQA. The 34th Conference on Computer Vision and Pattern Recognition (CVPR), 2021. | [Link] [Code] |
 |
Yuandong Tian, Lantao Yu, Xinlei Chen, Surya Ganguli. Understanding Self-supervised Learning with Dual Deep Networks. ArXiv, 2020. | [Link] [Video] |
 |
Corentin Dancette*, Remi Cadene*, Xinlei Chen, Matthieu Cord. Overcoming Statistical Shortcuts for Open-ended Visual Counting. ArXiv, 2020. | [Link] [Code] |
 |
Duy-Kien Nguyen, Vedanuj Goswami, Xinlei Chen. Revisiting Modulated Convolutions for Visual Counting and Beyond. The 9th International Conference on Learning Representations (ICLR), 2021. VQA 2020 Challenge Winner. | [Link] [Code] |
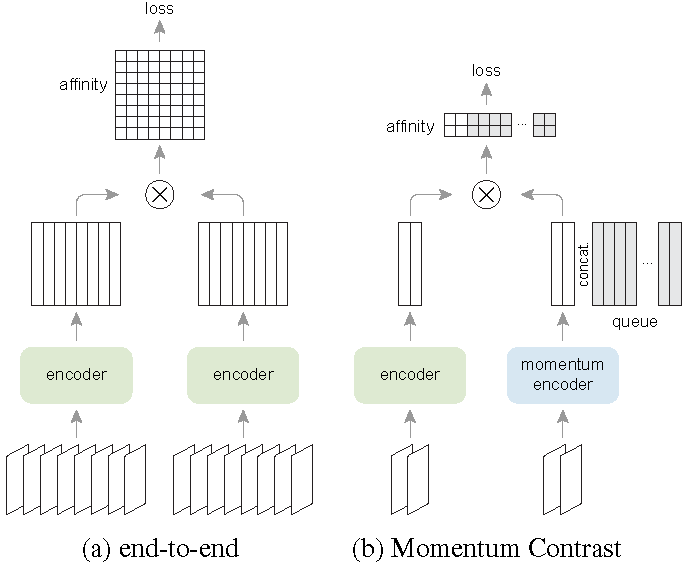 |
Xinlei Chen, Haoqi Fan, Ross Girshick, Kaiming He. Improved Baselines with Momentum Contrastive Learning. ArXiv, 2020. | [Link] [Code] |
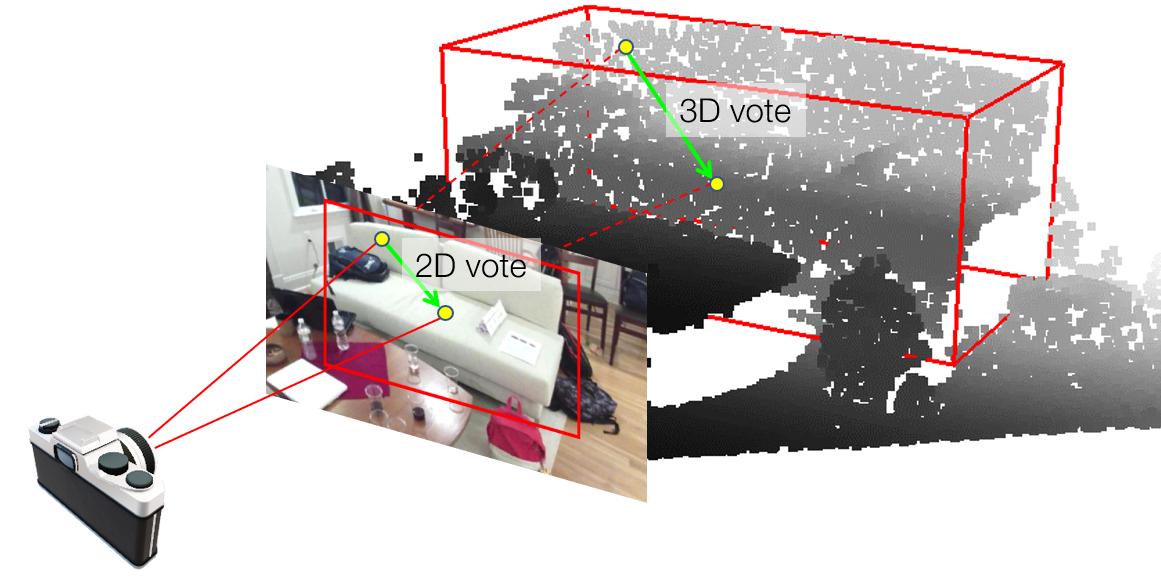 |
Charles R. Qi*, Xinlei Chen*, Or Litany, Leonidas J. Guibas. ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes. The 33rd Conference on Computer Vision and Pattern Recognition (CVPR), 2020. | [Link] [Code] |
 |
Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik Learned-Miller, Xinlei Chen. In Defense of Grid Features for Visual Question Answering. The 33rd Conference on Computer Vision and Pattern Recognition (CVPR), 2020. | [Link] [Code] |
 |
Xinlei Chen, Ross Girshick, Kaiming He, Piotr Dollár. TensorMask: A Foundation for Dense Object Segmentation. The 17th International Conference on Computer Vision (ICCV), 2019. | [Link] [Code] |
 |
Zhuoyuan Chen*, Demi Guo*, Tong Xiao*, Saining Xie, Xinlei Chen, Haonan Yu, Jonathan Gray, Kavya Srinet, Haoqi Fan, Jerry Ma, Charles R Qi, Shubham Tulsiani, Arthur Szlam, C Lawrence Zitnick. Order-Aware Generative Modeling Using the 3D-Craft Dataset. The 17th International Conference on Computer Vision (ICCV), 2019. | [Link] [Code] [Data] |
 |
Harsh Agrawal*, Karan Desai*, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, Peter Anderson. nocaps: novel object captioning at scale. The 17th International Conference on Computer Vision (ICCV), 2019. | [Link] [Project] |
 |
Meet Shah, Xinlei Chen, Marcus Rohrbach, Devi Parikh. Cycle-Consistency for Robust Visual Question Answering. The 32nd Conference on Computer Vision and Pattern Recognition (CVPR), 2019. Oral. | [Link] [Project] [Code] |
 |
Luowei Zhou, Yannis Kalantidis, Xinlei Chen, Jason J. Corso, Marcus Rohrbach. Grounded Video Description. The 32nd Conference on Computer Vision and Pattern Recognition (CVPR), 2019. Oral. | [Link] [Code(Data)] |
 |
Licheng Yu, Xinlei Chen, Georgia Gkioxari, Mohit Bansal, Tamara L. Berg, Dhruv Batra. Multi-Target Embodied Question Answering. The 32nd Conference on Computer Vision and Pattern Recognition (CVPR), 2019. | [Link] [Video] [Code] |
 |
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, Marcus Rohrbach. Towards VQA Models That Can Read. The 32nd Conference on Computer Vision and Pattern Recognition (CVPR), 2019. | [Link] [Project] [Code] |
 |
Jin-Hwa Kim, Nikita Kitaev, Xinlei Chen, Marcus Rohrbach, Yuandong Tian, Dhruv Batra, Devi Parikh. CoDraw: Collaborative Drawing as a Testbed for Grounded Goal-driven Communication. The 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019. | [Link] [Code(Data)] |
 |
Yu Jiang*, Vivek Natarajan*, Xinlei Chen*, Marcus Rohrbach, Dhruv Batra, Devi Parikh. Pythia v0.1: the Winning Entry to the VQA Challenge 2018. ArXiv, 2018. VQA 2018 Challenge Winner. | [Link] [Code] |
 |
Xinlei Chen, Li-Jia Li, Li Fei-Fei, Abhinav Gupta. Iterative Visual Reasoning Beyond Convolutions. The 31st Conference on Computer Vision and Pattern Recognition (CVPR), 2018. Spotlight. | [Link] [PDF] [Code] |
 |
Xinlei Chen. Visual Knowledge Learning. Doctoral Dissertation, CMU-LTI-18-001. | [PDF] [Slides] |
 |
Xinlei Chen, Abhinav Gupta. Spatial Memory for Context Reasoning in Object Detection. The 16th International Conference on Computer Vision (ICCV), 2017. | [Link] [PDF] [Poster] |
 |
Xinlei Chen, Abhinav Gupta. An Implementation of Faster RCNN with Study for Region Sampling. ArXiv, 2017. | [Link] [Code] |
| Aayush Bansal, Xinlei Chen, Bryan Russell, Abhinav Gupta, Deva Ramanan. PixelNet: Representation of the pixels, by the pixels, and for the pixels. ArXiv, 2017. | [Link] [Project] [Code] [Code(Old)] | |
 |
Gunnar A. Sigurdsson, Xinlei Chen, Abhinav Gupta. Learning Visual Storylines with Skipping Recurrent Neural Networks. The 14th European Conference on Computer Vision (ECCV), 2016. | [Link] [PDF] [Poster] [Code] |
 |
Jiwei Li, Xinlei Chen, Eduard Hovy, Dan Jurafsky. Visualizing and Understanding Neural Models in NLP. Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2016. | [Link] [PDF] [Code] |
 |
Xinlei Chen, Abhinav Gupta. Webly Supervised Learning of Convolutional Networks. The 15th International Conference on Computer Vision (ICCV), 2015. Oral. | [Link] [PDF] [Slides] [Poster] [Video] [Talk] [Code] [Project] |
 |
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollar, C. Lawrence Zitnick. Microsoft COCO Captions: Data Collection and Evaluation Server. Arxiv Preprint, 2015. | [Link] [Code] |
 |
Xinlei Chen, C. Lawrence Zitnick. Mind's Eye: A Recurrent Visual Representation for Image Caption Generation. The 28th Conference on Computer Vision and Pattern Recognition (CVPR), 2015. | [PDF] [Poster] |
 |
Xinlei Chen, Alan Ritter, Abhinav Gupta, Tom Mitchell. Sense Discovery via Co-Clustering on Images and Text. The 28th Conference on Computer Vision and Pattern Recognition (CVPR), 2015. | [PDF] [Poster] [Project] |
 |
Xinlei Chen, Abhinav Shrivastava, Abhinav Gupta. Enriching Visual Knowledge Bases via Object Discovery and Segmentation. The 27th Conference on Computer Vision and Pattern Recognition (CVPR), 2014. | [PDF][Poster][Project][Code] |
 |
Xinlei Chen, Abhinav Shrivastava, Abhinav Gupta. NEIL: Extracting Visual Knowledge from Web Data. The 14th International Conference on Computer Vision (ICCV), 2013. Oral. | [PDF] [Slides] [Poster] [Web] [Talk] [Code] [Test Code] |
 |
Xinlei Chen, Deng Cai. Large Scale Spectral Clustering with Landmark-based Representation. The 26th AAAI Conference on Artificial Intelligence (AAAI), 2011. | [PDF][Code] |
 |
Jiajun Lv, Xinlei Chen, Jin Huang, Hujun Bao. Semi-supervised Mesh Segmentation and Labeling. The 20th Pacific Conference on Computer Graphics and Applications (PG), 2012. | [PDF][Project] |